

Hello everyone Varsha here with the new article based on a passive information gathering tool named as theHarvester tool. theHarvester is a tool for gathering email addresses, subdomains, hosts, employee names, open ports, and banners from different public sources.
After reading this article you will definitely be able to install and run theHarvester tool on your system, and you can also learn how you can use it.
What is theHarvester tool?
theHarvester is a tool for gathering email addresses, subdomains, hosts, employee names, open ports, and banners from different public sources (search engines, PGP key servers). It is designed to be used in the full reconnaissance and information-gathering phases of a penetration test. This tool is useful for finding potential targets on a network and gathering information about a company or organization. It can also be used to verify the security of your own email server.
Installing in Kali Linux
to install theHarvester tool in kali Linux follow the following steps:
Steps
Step 1
download theharvester tool from theharvester GitHub page
git clone https://github.com/laramies/theHarvester Output:
┌──(kali㉿kali)-[~]
└─$ git clone https://github.com/laramies/theHarvester
Cloning into 'theHarvester'...
remote: Enumerating objects: 12250, done.
remote: Counting objects: 100% (69/69), done.
remote: Compressing objects: 100% (50/50), done.
remote: Total 12250 (delta 27), reused 51 (delta 19), pack-reused 12181
Receiving objects: 100% (12250/12250), 7.00 MiB | 213.00 KiB/s, done.
Resolving deltas: 100% (7699/7699), done.
Step 2
navigate to theharvester directory
cd theHarvesterOutput:
(kali㉿kali)-[~]
└─$ cd theHarvesterStep 3
install python3-pip in theharvester directory
sudo apt install python3-pipOutput:
(kali㉿kali)-[~/theHarvester]
└─$ sudo apt install python3-pip
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
The following additional packages will be installed:
python3-pip-whl
The following packages will be upgraded:
python3-pip python3-pip-whl
2 upgraded, 0 newly installed, 0 to remove and 1433 not upgraded.
Need to get 3,034 kB of archives.
After this operation, 61.4 kB of additional disk space will be used.
Do you want to continue? [Y/n] y
Get:1 http://http.kali.org/kali kali-rolling/main amd64 python3-pip all 22.3+dfsg-1 [1,322 kB]
Get:2 http://http.kali.org/kali kali-rolling/main amd64 python3-pip-whl all 22.3+dfsg-1 [1,712 kB]
Fetched 3,034 kB in 10s (296 kB/s)
(Reading database ... 348245 files and directories currently installed.)
Preparing to unpack .../python3-pip_22.3+dfsg-1_all.deb ...
Unpacking python3-pip (22.3+dfsg-1) over (22.2+dfsg-1) ...
Preparing to unpack .../python3-pip-whl_22.3+dfsg-1_all.deb ...
Unpacking python3-pip-whl (22.3+dfsg-1) over (22.2+dfsg-1) ...
Setting up python3-pip-whl (22.3+dfsg-1) ...
Setting up python3-pip (22.3+dfsg-1) ...
Processing triggers for man-db (2.10.2-1) ...
Processing triggers for kali-menu (2022.3.1) ...Step 4
install basic requirements from dev.txt file in theharvester directory
python3 -m pip install -r requirements/dev.txt
#else:
python3 -m pip install -r requirements/base.txtOutput:
(kali㉿kali)-[~/theHarvester]
└─$ python3 -m pip install -r requirements/dev.txt
Defaulting to user installation because normal site-packages is not writeable
Requirement already satisfied: aiodns==3.0.0 in /usr/lib/python3/dist-packages (from -r requirements/base.txt (line 1)) (3.0.0)
Collecting aiofiles==22.1.0
Downloading aiofiles-22.1.0-py3-none-any.whl (14 kB)
Collecting aiohttp==3.8.3
Downloading aiohttp-3.8.3-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.0/1.0 MB 101.7 kB/s eta 0:00:00
Collecting aiomultiprocess==0.9.0
Downloading aiomultiprocess-0.9.0-py3-none-any.whl (17 kB)
Requirement already satisfied: aiosqlite==0.17.0 in /usr/lib/python3/dist-packages (from -r requirements/base.txt (line 5)) (0.17.0)
Requirement already satisfied: beautifulsoup4==4.11.1 in /usr/lib/python3/dist-packages (from -r requirements/base.txt (line 6)) (4.11.1)
Collecting censys==2.1.9
Downloading censys-2.1.9-py3-none-any.whl (53 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 53.7/53.7 kB 233.7 kB/s eta 0:00:00
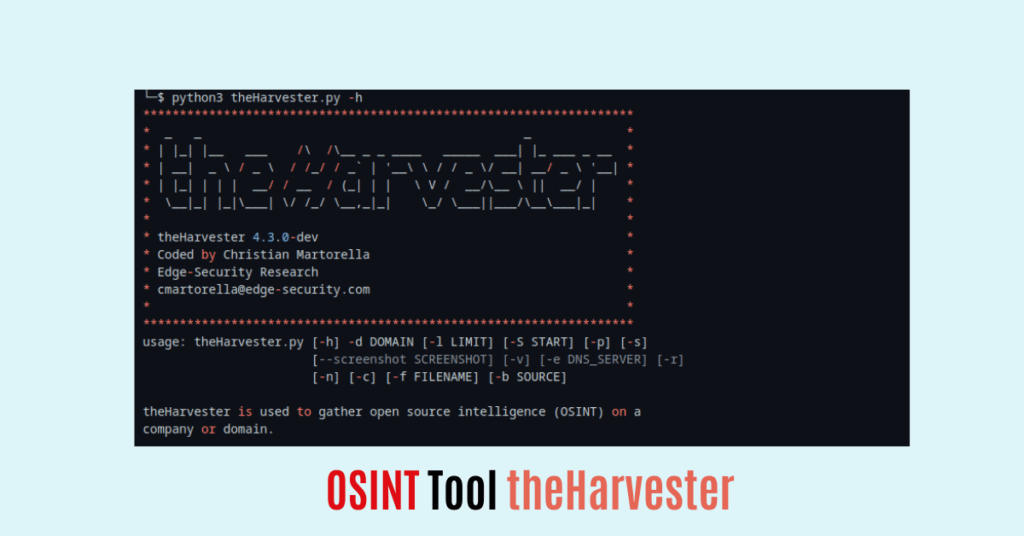
Step 5
Run theharvester tool by executing this command
python3 theHarvester.py -h Output:
(kali㉿kali)-[~/theHarvester]
└─$ python3 theHarvester.py -h
*******************************************************************
* _ _ _ *
* | |_| |__ ___ /\ /\__ _ _ ____ _____ ___| |_ ___ _ __ *
* | __| _ \ / _ \ / /_/ / _` | '__\ \ / / _ \/ __| __/ _ \ '__| *
* | |_| | | | __/ / __ / (_| | | \ V / __/\__ \ || __/ | *
* \__|_| |_|\___| \/ /_/ \__,_|_| \_/ \___||___/\__\___|_| *
* *
* theHarvester 4.3.0-dev *
* Coded by Christian Martorella *
* Edge-Security Research *
* cmartorella@edge-security.com *
* *
*******************************************************************
usage: theHarvester.py [-h] -d DOMAIN [-l LIMIT] [-S START] [-p] [-s]
[--screenshot SCREENSHOT] [-v] [-e DNS_SERVER] [-r]
[-n] [-c] [-f FILENAME] [-b SOURCE]
theHarvester is used to gather open source intelligence (OSINT) on a
company or domain.
options:
-h, --help show this help message and exit
-d DOMAIN, --domain DOMAIN
Company name or domain to search.
-l LIMIT, --limit LIMIT
Limit the number of search results, default=500.
-S START, --start START
Start with result number X, default=0.
-p, --proxies Use proxies for requests, enter proxies in
proxies.yaml.
-s, --shodan Use Shodan to query discovered hosts.
--screenshot SCREENSHOT
Take screenshots of resolved domains specify output
directory: --screenshot output_directory
-v, --virtual-host Verify host name via DNS resolution and search for
virtual hosts.
-e DNS_SERVER, --dns-server DNS_SERVER
DNS server to use for lookup.
-r, --take-over Check for takeovers.
-n, --dns-lookup Enable DNS server lookup, default False.
-c, --dns-brute Perform a DNS brute force on the domain.
-f FILENAME, --filename FILENAME
Save the results to an XML and JSON file.
-b SOURCE, --source SOURCE
anubis, baidu, bevigil, binaryedge, bing, bingapi,
bufferoverun, censys, certspotter, crtsh,
dnsdumpster, duckduckgo, fullhunt, github-code,
hackertarget, hunter, intelx, otx, pentesttools,
projectdiscovery, qwant, rapiddns, rocketreach,
securityTrails, sublist3r, threatcrowd,
threatminer, urlscan, virustotal, yahoo, zoomeye
Step 6
use theharvester tool feature by giving a domain name in the command
python3 theHarvester.py -d <DOMAIN NAME> -l 500 -b <SOURCE>Output:

Why do we use theHarvester tool?
- To perform reconnaissance on a target domain or organization.
- To identify potential email addresses or usernames for employees of a target organization.
- Gather information about the target organization’s publicly available servers and web applications.
- To identify potential vulnerabilities or weak points in the target organization’s online presence.
- To gather intelligence for use in a penetration test or red teaming exercise.
Related questions asked
1. Is theHarvester active or passive?
theHarvester is a passive information-gathering tool
2. How do I update my harvester?
You can directly update your theharvester tool from the system aptitude update
3. What services data sources does theHarvester use to gather information?
theHarvester to use different search engines, and PGP key servers to gather information
Youtube Video for better clarification
If you have any queries regarding the above content, or you want to update anything in the content, then contact us with your queries. You can directly post your question in the group.
Connect with us on these platforms